로컬 AI 모델 내 컴퓨터에서 돌릴 수 있을까? 사양 측정 완전 가이드
제 노트북도 AI를 돌렸다는데, 실제로 가능할까?
저도 처음엔 헷갈렸어요.
“로컬 AI 모델”이라는 말은 자주 들었는데, 정작 ‘내 컴퓨터로 정말 돌릴 수 있나?’는 질문에는 명확한 답이 없었거든요. 클라우드 서비스는 비용이 계속 나가고, 로컬에서 뭔가 띄울 수 있다고 해도 구체적으로 뭘 체크해야 할지 몰랐습니다.
그런데 CanIRun.ai라는 사이트를 발견하고는 상황이 달라졌어요.
GPU 메모리, RAM, CPU 코어 수를 입력하면, 당신이 실제로 돌릴 수 있는 AI 모델을 정확하게 보여주는 도구였거든요.
이 글에서는 CanIRun.ai를 활용해서 로컬 AI 모델 요구사양을 체크하는 방법을 단계별로 정리해봤습니다.
CanIRun.ai란? 로컬 AI 모델 요구사양 한눈에 파악하기
간단해요.
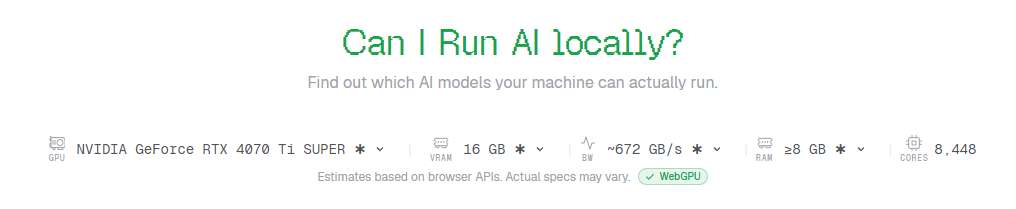
내 컴퓨터의 사양을 입력하면, 돌릴 수 있는 AI 모델을 즉시 알려주는 사이트입니다. 사이트에 접속해보세요. 제 컴퓨터 사양을 즉시 알아냅니다.
CanIRun.ai는 자신의 GPU(그래픽카드), RAM, CPU 정보를 브라우저에서 자동 감지하거나 수동으로 입력할 수 있습니다.
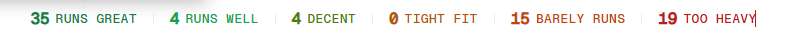
그러면 수십 개의 오픈소스 AI 모델(Llama, Qwen, Mistral 등)에 대해 숫자로 간단하게 쓰기 좋은 모델을 알려줘.
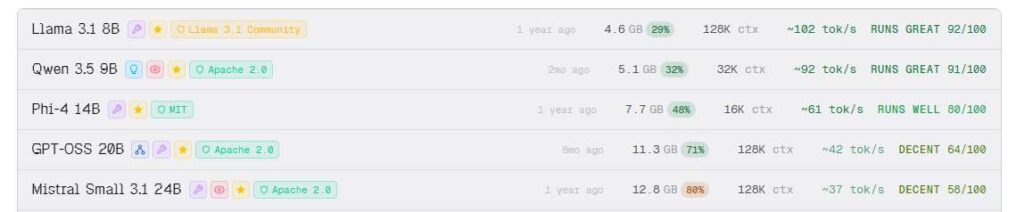
듣지도 못한 AI 로컬 모델이 무수하게 많은데요.

필터기능도 있어서 쓰임을 고를 수 있습니다.
저는 다음번에 쓰고 싶은 게 비전인데요. 모델 알아볼 때 좋아요.
- S/A/B 등급: 실행 가능성 (S=완벽, F=불가)
- 필요 VRAM: GPU 메모리 용량
- 권장 RAM: 시스템 메모리
- 매개변수 수(B): 모델 크기
- 컨텍스트 길이: 처리할 수 있는 텍스트 양
제가 직접 해보지는 않았지만, 메타의 Ollama 이용해서 활용하면 좋을 듯 싶어요.
내 PC를 무료 AI 코딩 비서로! Aider + Ollama (Qwen 2.5) 완벽 연동 가이드
내 컴퓨터가 AI를 돌릴 수 있을까? – VRAM·GPU 메모리 체크 방법
여기가 핵심이에요.
로컬 AI 모델을 돌리려면 GPU 메모리(VRAM)가 가장 중요합니다.
VRAM이란? 그래픽카드에 탑재된 독립 메모리예요.
일반 RAM(시스템 메모리)과는 다르고, GPU 연산 속도를 크게 좌우합니다.
CanIRun.ai 사용법:
- 사이트 접속 후 우측 상단의 GPU, VRAM, RAM, CPU 정보가 자동 표시
- “Detecting…” 문구가 사라질 때까지 잠깐 기다림
- 아래 모델 리스트를 보면, 각 모델 옆에 필요 VRAM(GB 단위) 표시
- 당신의 VRAM과 비교해서 “Green(완벽)” 또는 “Yellow(가능)” 항목 선택
실제 예: RTX 4060(8GB VRAM) 사용자라면?
- Llama 3.1 8B: 4.6GB → 완벽하게 돌음
- Qwen 3 8B: 4.6GB → 완벽하게 돌음
- Llama 3.3 70B: 36.4GB → 불가능 (VRAM 부족)
Llama부터 Qwen까지 – 실제 모델별 필요사양 비교표
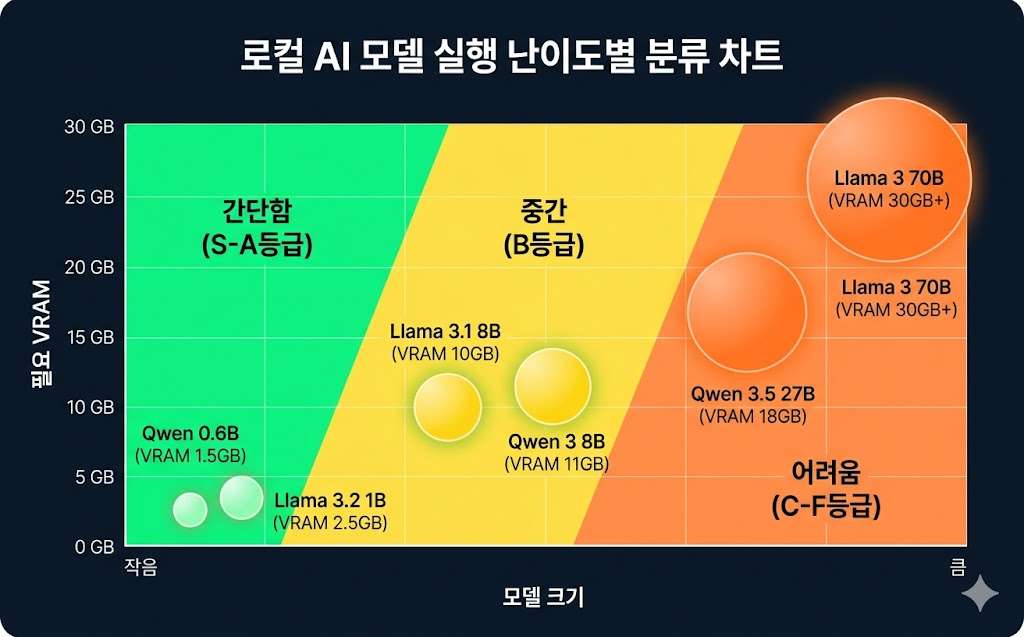
실제로 자주 쓰는 로컬 AI 모델의 사양을 정리해봤습니다.
| 모델명 | 매개변수 | 필요 VRAM | 권장 RAM | 용도 | CanIRun 등급 |
|---|---|---|---|---|---|
| Qwen 3.5 0.8B | 0.8B | 0.9GB | 2GB 이상 | 엣지 디바이스, 모바일 | A |
| Llama 3.2 1B | 1B | 1GB | 4GB 이상 | 초저전력, 라즈베리파이 | A |
| Llama 3.1 8B | 8B | 4.6GB | 16GB 권장 | 일반 사무, 코딩 | A |
| Qwen 2.5 14B | 14B | 7.7GB | 24GB 권장 | 복잡한 추론 | B |
| Gemma 3 27B | 27B | 14.3GB | 32GB 권장 | 고급 분석, 창의성 | C |
| Qwen 3.5 27B | 27.8B | 14.7GB | 32GB+ | 멀티모달(이미지+텍스트) | C |
| Llama 3.3 70B | 70B | 36.4GB | 64GB+ | 최고 수준 품질 | D |
핵심 팁: VRAM이 부족하면 양자화(Quantization) 기법으로 모델을 압축할 수 있습니다.
CanIRun에서는 Q2_K, Q4_K_M 같은 형식이 바로 그것인데, 메모리를 30~50%까지 줄일 수 있어요.
체크리스트: 로컬 AI 모델 선택 전 확인할 10가지
실제로 모델을 깔기 전에, 이 10가지를 점검하세요.
- 내 그래픽카드의 VRAM이 몇 GB인지 확인했나? (제어판 > 그래픽 설정에서 확인)
- 시스템 RAM이 16GB 이상인지 체크했나? (적어도 8GB는 있어야 부드러움)
- CanIRun.ai에서 내 사양을 입력해봤나? (정확한 GPU 모델명 필요)
- “A 또는 B 등급” 모델부터 시작하기로 결정했나? (C 이상은 고사양 필요)
- 필요한 모델의 용도(Chat/Code/Reasoning)가 내 목표와 맞는지 확인했나?
- 로컬 실행 소프트웨어 준비했나? (Ollama, LM Studio, GPT4All 중 선택)
- 모델 파일 저장할 디스크 공간이 충분한가? (8B 모델도 최소 20GB 필요)
- 인텔/AMD GPU일 경우 드라이버는 최신인가? (CUDA/ROCm 호환성 확인)
- 첫 로드 시간이 깨질 수 있다는 걸 알고 있나? (초기 다운로드는 느릴 수 있음)
- 클라우드 대비 비용을 계산해봤나? (전기료 vs 구독료)
로컬 AI 모델 선택, 더 이상 막힐 필요 없겠죠? 혹시 당신의 컴퓨터 사양을 CanIRun.ai에 입력해봤다면, 어떤 모델이 작동했는지 댓글로 나눠주세요!
2026년 4월 GPU 순위 및 게이밍 용도별 최적 그래픽카드 추천 가이드


![[워드프레스] “Briefly unavailable for scheduled maintenance” 1분 만에 해결하기](https://nightwelfare.kr/wp-content/uploads/2026/02/image-78-768x768.jpg)


